오늘은 IntelliJ라는 JAVA를 다루는 분들이라면 많이 사용하시는 IDE를 이용하여 프로젝트를 war파일로 배포하고, 외장 톰캣에 배포하려고합니다. Legacy프로젝트는 war파일로 배포하는것이 굉장히 쉬웠는데, spring boot 프로젝트는 몇가지 변경점이 있고 내장, 외장 톰캣 구동에 차이가 있지만 외장 톰캣 배포방법에 대해서만 다루겠습니다.
이 글을 보시는 분들은 대부분 프로젝트의 테스트를 마무리하고 배포하시려는 분들이 많다고 생각됩니다. 따라서 기존 프로젝트가 있으시면 2번부터 보시면 되겠습니다.
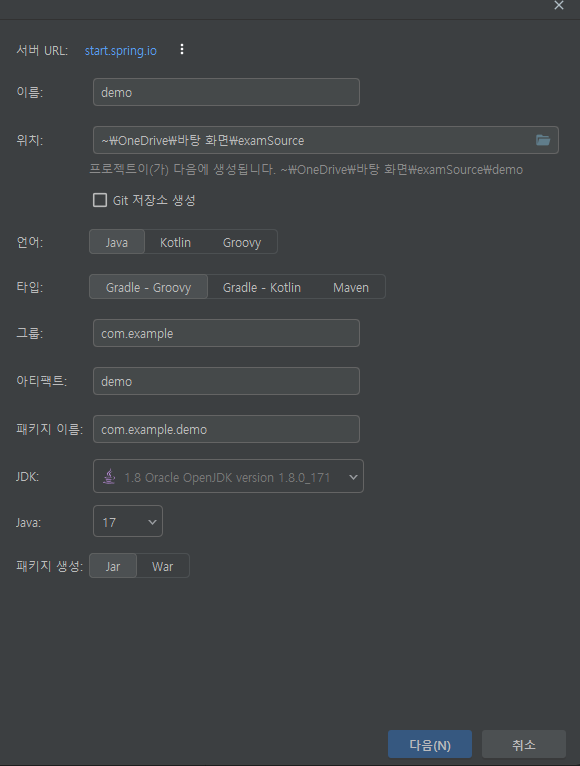
우선 배포할 프로젝트가 있어야합니다. 스프링 부트 프로젝트 생성법은 하단 링크를 참고해주세요.
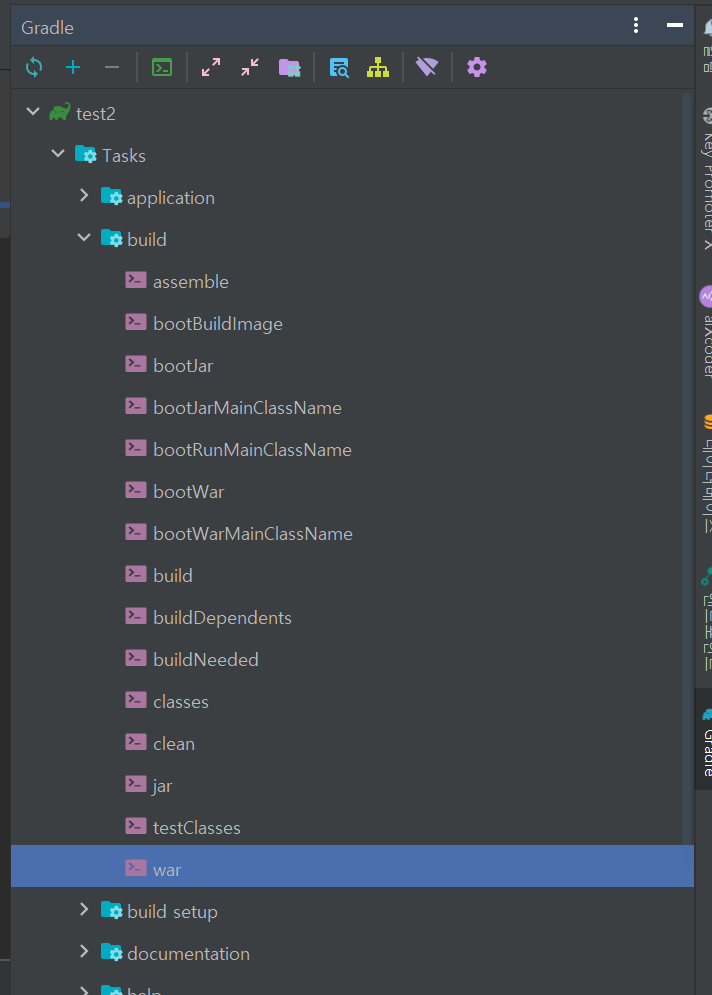
우선 빌드하실때 build에 들어가면 해당 디렉토리들이 보이실텐데요. bootWar이나 bootJar은 내장 톰캣에서 프로젝트를 구동할 때 사용됩니다. 때문에 밑에 있는 war이나 jar로 배포해야한다는 점 미리 말씀드리겠습니다.
이부분은 첫 사진의 war라는 이름의 메뉴를 추가해주는 부분입니다.
또한 이 부분을 build.gradle에 추가합니다. 맨 윗사진의 war라는 이름의 플러그인을 실행할 수 있게해주는 구문입니다.
위 부분은 위에서 설명드린 것과 같이 내장톰캣전용인 bootWar의 빌드를 제한해주고 war파일을 만들게 해주는데, 두가지가 충돌하지 않게 직접 사용도를 지정한겁니다. 내장용으로 받으실거면 bool값을 반대로 주시면되겠죠?
해당 부분은 배포될 war파일의 파일명, 버젼등을 지정하는 부분입니다.
이렇게 되면 build.gradle파일의 수정은 완료됩니다. 전체 코드 사진을 보여드리고 다음 단계로 넘어가겠습니다.
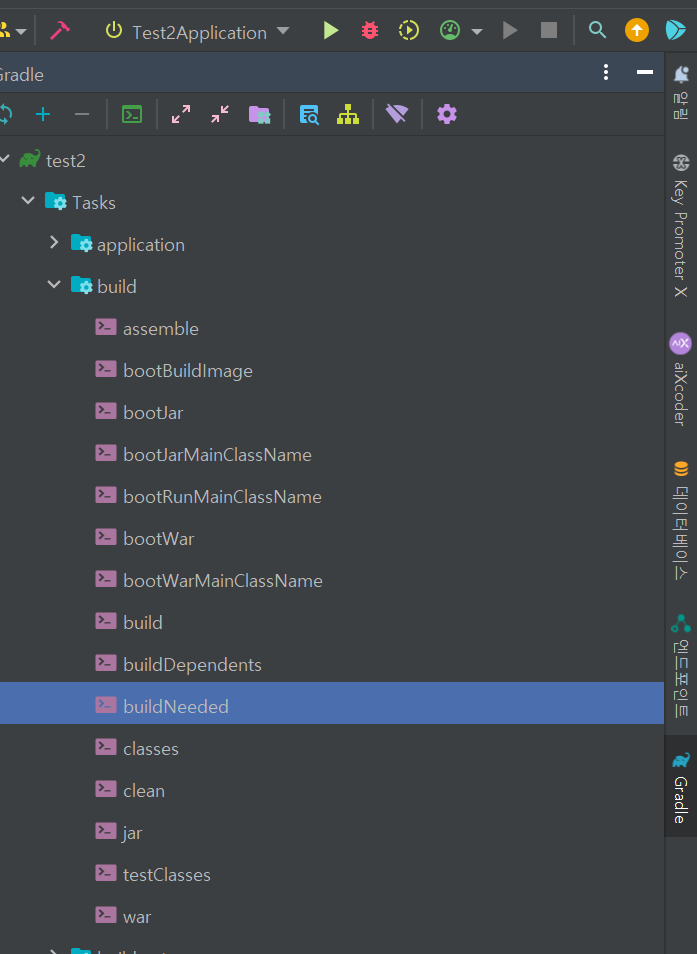
해당 설정까지 완료하셨으면 아래 사진과같이 gradle 메뉴를 열고 war메뉴를 실행하시면됩니다.
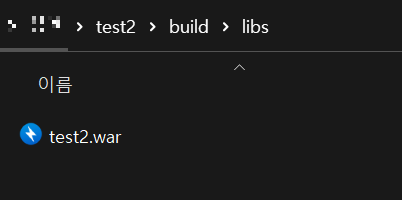
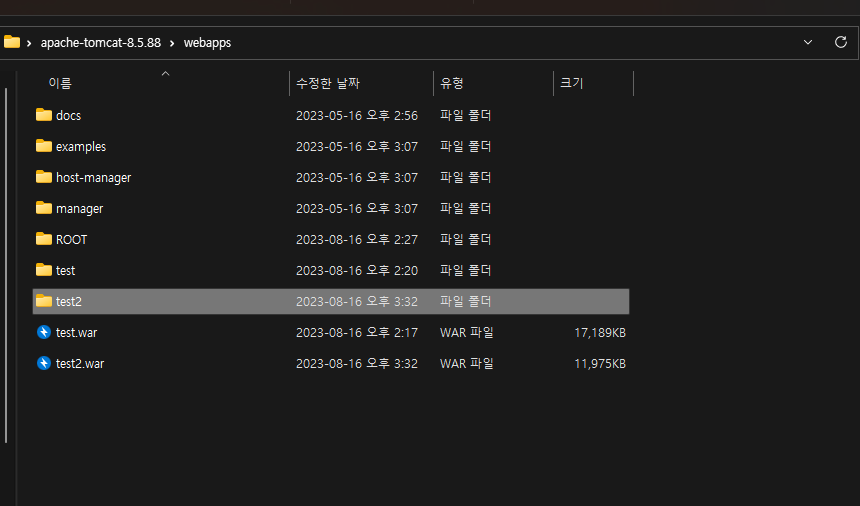
그리고 프로젝트 경로/build/libs 파일에 보시면 제가 설정한대로 .war파일이 생성되었습니다.
이후 설치한 외장 톰캣 파일의 webapps 옮기시면됩니다. 아래 사진같은 경우는 제가 따로 실행시킨 test.war파일이 있습니다.
또한 5번에서 세팅을 할 것인데. 이런 방법 없이 바로 실행되었으면 좋겠다 하시는 분들은 war파일을 root.war로 바꿔서 넣으시면됩니다. 기본적으로 톰캣은 root.war을 바라보고 있기 때문입니다.
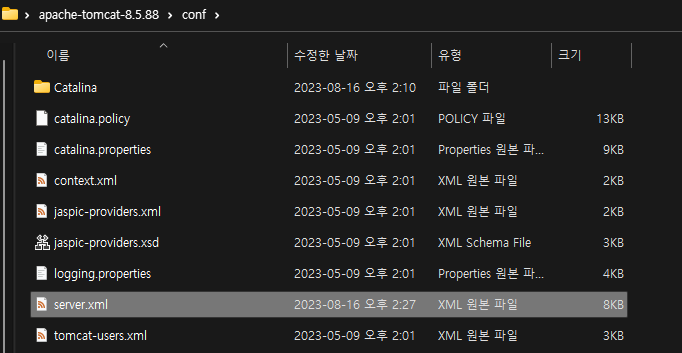
이후 톰캣 경로/conf파일의 server.xml에 들어가 설정을 해주어야합니다.
라는 부분을 추가할 것인데. path는 localhost:포트번호 다음에 입력할 프로젝트의 경로를 지정하는 것입니다.
reloadable은 war파일을 업데이트해서 바꿔치기를 하면 적용이 바로 되도록하는 것입니다. 개발시에는 true가 편하고, 운영시에는 당연히 false로 놓아야합니다.
아래는 server.xml의 전체 코드입니다.
<?xml version="1.0" encoding="UTF-8"?>
<!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<!-- Note: A "Server" is not itself a "Container", so you may not
define subcomponents such as "Valves" at this level.
Documentation at /docs/config/server.html
-->
<Server port="8005" shutdown="SHUTDOWN">
<Listener className="org.apache.catalina.startup.VersionLoggerListener" />
<!-- Security listener. Documentation at /docs/config/listeners.html
<Listener className="org.apache.catalina.security.SecurityListener" />
-->
<!-- APR library loader. Documentation at /docs/apr.html -->
<Listener className="org.apache.catalina.core.AprLifecycleListener" SSLEngine="on" />
<!-- Prevent memory leaks due to use of particular java/javax APIs-->
<Listener className="org.apache.catalina.core.JreMemoryLeakPreventionListener" />
<Listener className="org.apache.catalina.mbeans.GlobalResourcesLifecycleListener" />
<Listener className="org.apache.catalina.core.ThreadLocalLeakPreventionListener" />
<!-- Global JNDI resources
Documentation at /docs/jndi-resources-howto.html
-->
<GlobalNamingResources>
<!-- Editable user database that can also be used by
UserDatabaseRealm to authenticate users
-->
<Resource name="UserDatabase" auth="Container"
type="org.apache.catalina.UserDatabase"
description="User database that can be updated and saved"
factory="org.apache.catalina.users.MemoryUserDatabaseFactory"
pathname="conf/tomcat-users.xml" />
</GlobalNamingResources>
<!-- A "Service" is a collection of one or more "Connectors" that share
a single "Container" Note: A "Service" is not itself a "Container",
so you may not define subcomponents such as "Valves" at this level.
Documentation at /docs/config/service.html
-->
<Service name="Catalina">
<!--The connectors can use a shared executor, you can define one or more named thread pools-->
<!--
<Executor name="tomcatThreadPool" namePrefix="catalina-exec-"
maxThreads="150" minSpareThreads="4"/>
-->
<!-- A "Connector" represents an endpoint by which requests are received
and responses are returned. Documentation at :
Java HTTP Connector: /docs/config/http.html
Java AJP Connector: /docs/config/ajp.html
APR (HTTP/AJP) Connector: /docs/apr.html
Define a non-SSL/TLS HTTP/1.1 Connector on port 8080
-->
<Connector port="8082" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443"
maxParameterCount="1000"
/>
<!-- A "Connector" using the shared thread pool-->
<!--
<Connector executor="tomcatThreadPool"
port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443"
maxParameterCount="1000"
/>
-->
<!-- Define an SSL/TLS HTTP/1.1 Connector on port 8443
This connector uses the NIO implementation. The default
SSLImplementation will depend on the presence of the APR/native
library and the useOpenSSL attribute of the AprLifecycleListener.
Either JSSE or OpenSSL style configuration may be used regardless of
the SSLImplementation selected. JSSE style configuration is used below.
-->
<!--
<Connector port="8443" protocol="org.apache.coyote.http11.Http11NioProtocol"
maxThreads="150" SSLEnabled="true"
maxParameterCount="1000"
>
<SSLHostConfig>
<Certificate certificateKeystoreFile="conf/localhost-rsa.jks"
type="RSA" />
</SSLHostConfig>
</Connector>
-->
<!-- Define an SSL/TLS HTTP/1.1 Connector on port 8443 with HTTP/2
This connector uses the APR/native implementation which always uses
OpenSSL for TLS.
Either JSSE or OpenSSL style configuration may be used. OpenSSL style
configuration is used below.
-->
<!--
<Connector port="8443" protocol="org.apache.coyote.http11.Http11AprProtocol"
maxThreads="150" SSLEnabled="true"
maxParameterCount="1000"
>
<UpgradeProtocol className="org.apache.coyote.http2.Http2Protocol" />
<SSLHostConfig>
<Certificate certificateKeyFile="conf/localhost-rsa-key.pem"
certificateFile="conf/localhost-rsa-cert.pem"
certificateChainFile="conf/localhost-rsa-chain.pem"
type="RSA" />
</SSLHostConfig>
</Connector>
-->
<!-- Define an AJP 1.3 Connector on port 8009 -->
<!--
<Connector protocol="AJP/1.3"
address="::1"
port="8009"
redirectPort="8443"
maxParameterCount="1000"
/>
-->
<!-- An Engine represents the entry point (within Catalina) that processes
every request. The Engine implementation for Tomcat stand alone
analyzes the HTTP headers included with the request, and passes them
on to the appropriate Host (virtual host).
Documentation at /docs/config/engine.html -->
<!-- You should set jvmRoute to support load-balancing via AJP ie :
<Engine name="Catalina" defaultHost="localhost" jvmRoute="jvm1">
-->
<Engine name="Catalina" defaultHost="localhost">
<!--For clustering, please take a look at documentation at:
/docs/cluster-howto.html (simple how to)
/docs/config/cluster.html (reference documentation) -->
<!--
<Cluster className="org.apache.catalina.ha.tcp.SimpleTcpCluster"/>
-->
<!-- Use the LockOutRealm to prevent attempts to guess user passwords
via a brute-force attack -->
<Realm className="org.apache.catalina.realm.LockOutRealm">
<!-- This Realm uses the UserDatabase configured in the global JNDI
resources under the key "UserDatabase". Any edits
that are performed against this UserDatabase are immediately
available for use by the Realm. -->
<Realm className="org.apache.catalina.realm.UserDatabaseRealm"
resourceName="UserDatabase"/>
</Realm>
<Host name="localhost" appBase="webapps"
unpackWARs="true" autoDeploy="true">
<Context path="" docBase="test" reloadable="true" />
<Context path="/test2" docBase="test2" reloadable="true" /> //추가
<!-- 새로운 프로젝트 추가 -->
<!-- SingleSignOn valve, share authentication between web applications
Documentation at: /docs/config/valve.html -->
<!--
<Valve className="org.apache.catalina.authenticator.SingleSignOn" />
-->
<!-- Access log processes all example.
Documentation at: /docs/config/valve.html
Note: The pattern used is equivalent to using pattern="common" -->
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="localhost_access_log" suffix=".txt"
pattern="%h %l %u %t "%r" %s %b" />
</Host>
</Engine>
</Service>
</Server>
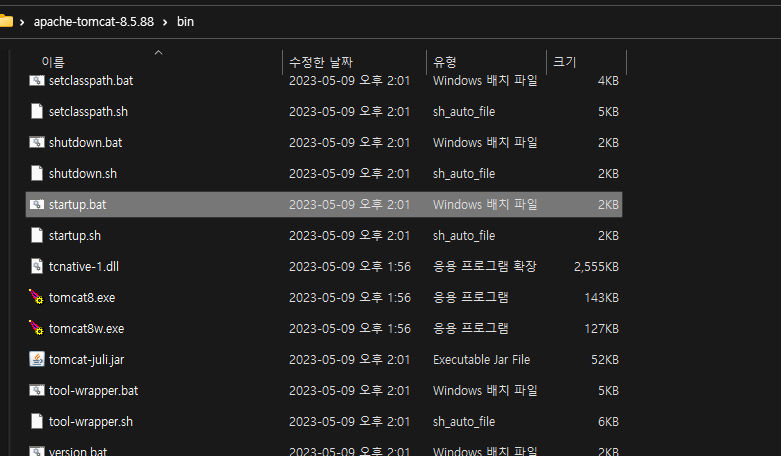
이제 톰캣경로/bin에 들어가 Window는 startup.bat, MacOs는 startup.sh를 눌러 실행시킨 후 webapps에 들어가 추가한 war파일과 이름이 같은 디렉터리가 생기는지 확인하고, startup에서 로그를 확인하며 에러가 발생하지 않는지 확인합니다.
우선 디렉터리가 생겼으면 반쯤 성공했다고 보시면됩니다.
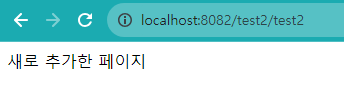
이제 웹에서 잘 나오는지 확인해보겠습니다. 저는 server.xml에서 localhost:포트번호/프로젝트명/test2를 입력하면 index파일이 나오게 설정해놓았습니다.
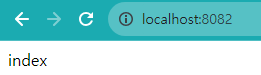
또한 미리 등록되있는 프로젝트는 포트명까지만 입력하면 작동되는 기본 프로젝트이므로, 그역시 작동되는지 확인하겠습니다.
모두 잘 작동되는 것을 확인했습니다. 이것으로 Spring Boot 프로젝트 외장 톰캣 배포에 대한 포스팅을 마치겠습니다.